Todas las áreas
Área Diseño y Artes
Área Internet
Área Programación
Área Reparación de Redes y Hardware
Área Informática Fundamental
Área Windows y Linux
Área Marketing y Gestión
Área Finanzas e Inversiones
Área Salud y Bienestar
Área Belleza e Imagen
Área Medio ambiente y Energías renovables
Área Turismo y Hostelería
Área Idiomas
Cursos cortos
Otros Cursos

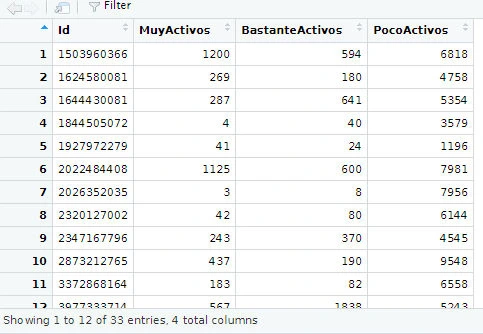
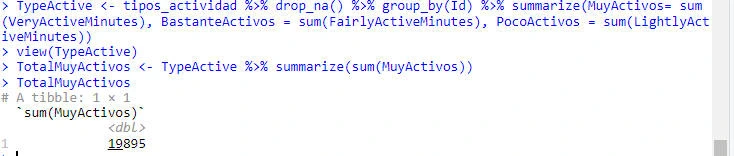

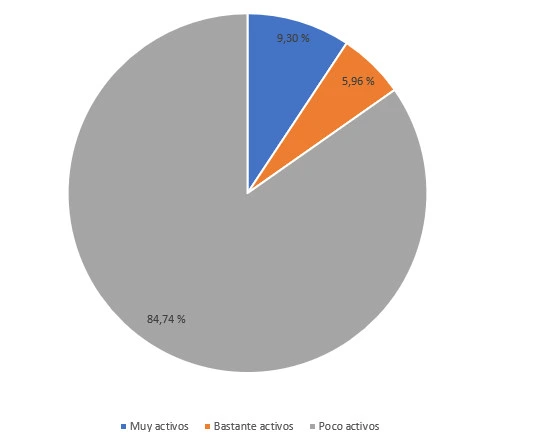
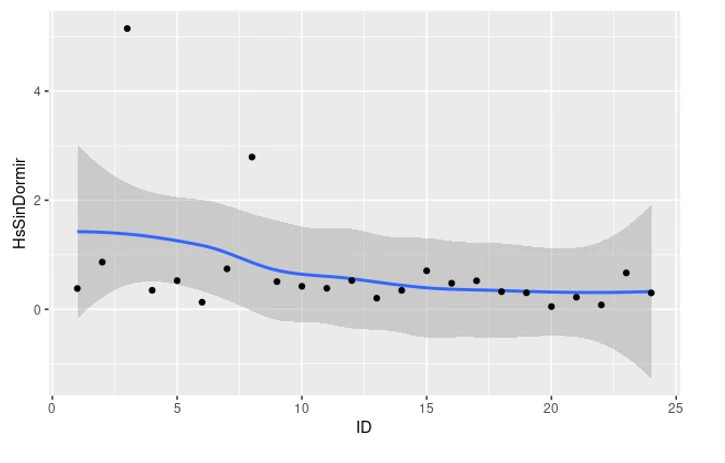
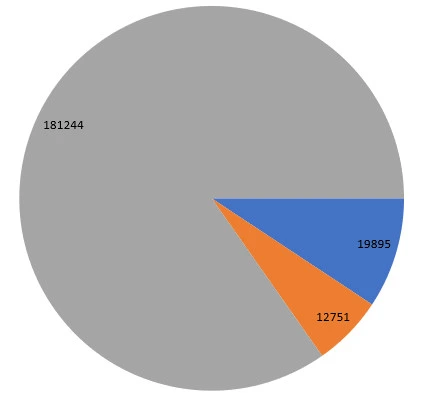 Tiempo en minutos.
Tiempo en minutos.